Mini-C Language Lexical Analyser
项目地址: github.com/aaroncomo/lexical-analysis
1 实验内容
构造一个小 (Mini) 语言的词法分析程序:
- 设计一个包含简单算术表达式、赋值语句、IF语句的小语言的文法
- 根据此文法, 构造一词法分析程序. 输入以#为结束符的源程序, 输出为各类单词表和单词串文件
- 源程序和输出的单词串均以文件的形式存放
- 单词的自身值均为其对应的表的指针, 如标识符表的指针、常数表的指针等
- 词法错误类型: 词法中未定义的宇符及任何不符合词法单元定义的宇符
2 实验环境
- 硬件: MacBook Air 2022
- CPU 架构: arm64
- 操作系统: macOS 13.1
- 编程环境: VS Code
- 编译器: g++
- C 标准: C++11
3 实验流程
3.1 形式化语言描述
构建的语言: Mini-C 语言
关键字表
main int long bool if else for do while return false true 符号表
> < = <= >= == != ; , + - ***** / ( ) { } digit string 数字和字符串文法
letter $\rightarrow$ letter ( letter | digit ) $^*$
letter $\rightarrow$ a | b | … | z | A | B | … | Y | Z
digit $\rightarrow$ digit $^+$
digit $\rightarrow$ 0 | 1 | … | 9
3.2 标识符编码
| 标识符 | 编码 | 标识符 | 编码 |
|---|---|---|---|
| main | 0 | == | 16 |
| int | 1 | != | 17 |
| if | 2 | + | 18 |
| else | 3 | - | 19 |
| while | 4 | * | 20 |
| do | 5 | / | 21 |
| for | 6 | ( | 22 |
| long | 7 | ) | 23 |
| bool | 8 | { | 24 |
| < | 9 | } | 25 |
| > | 10 | digit | 26 |
| = | 11 | string | 27 |
| ; | 12 | return | 28 |
| , | 13 | false | 29 |
| <= | 14 | true | 30 |
| >= | 15 |
3.3 自动机
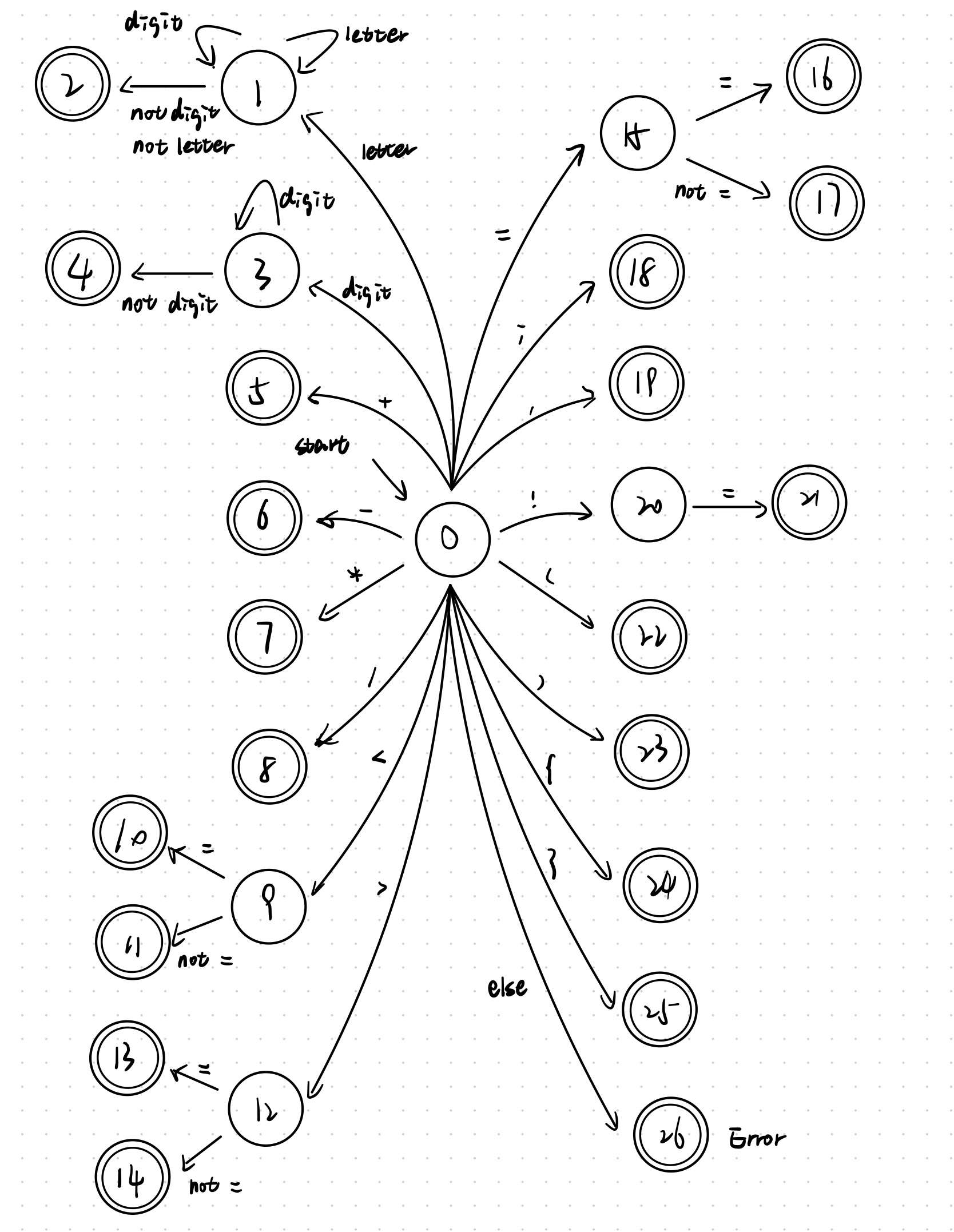
3.4 编写程序
3.4.1 状态机类
编写词法分析状态机类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
class Atomation { private: string tokens; // recognized characters bool endsWith[3] = { ... }; set<string> s = { ... } unordered_map<string, int> symbolTable { ... } unordered_map<string, vector<string> > table { ... } unordered_map<string, int> ends { ... } bool inSet(const string c) { ... } int getNextState(const string state, string c) { ... } inline void next(FILE *stdin, char *buff, string &str) { ... } public: void run(FILE *stdin, FILE *stdout) { ... } };
创建标识符号表

根据 3.3 中自动机定义状态转换表
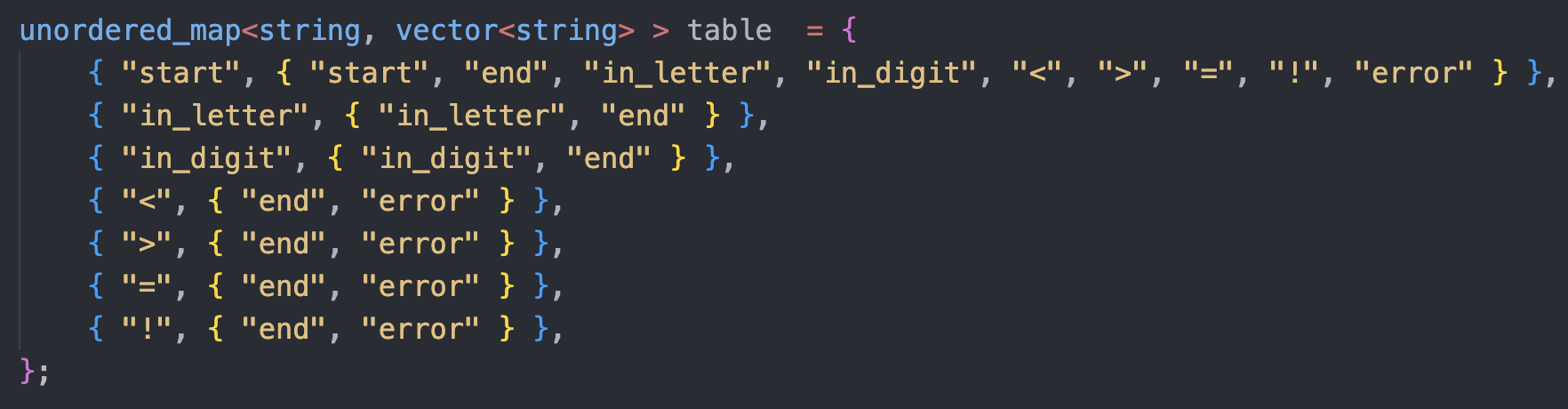
根据状态转换关系, 编写获取下一状态方法
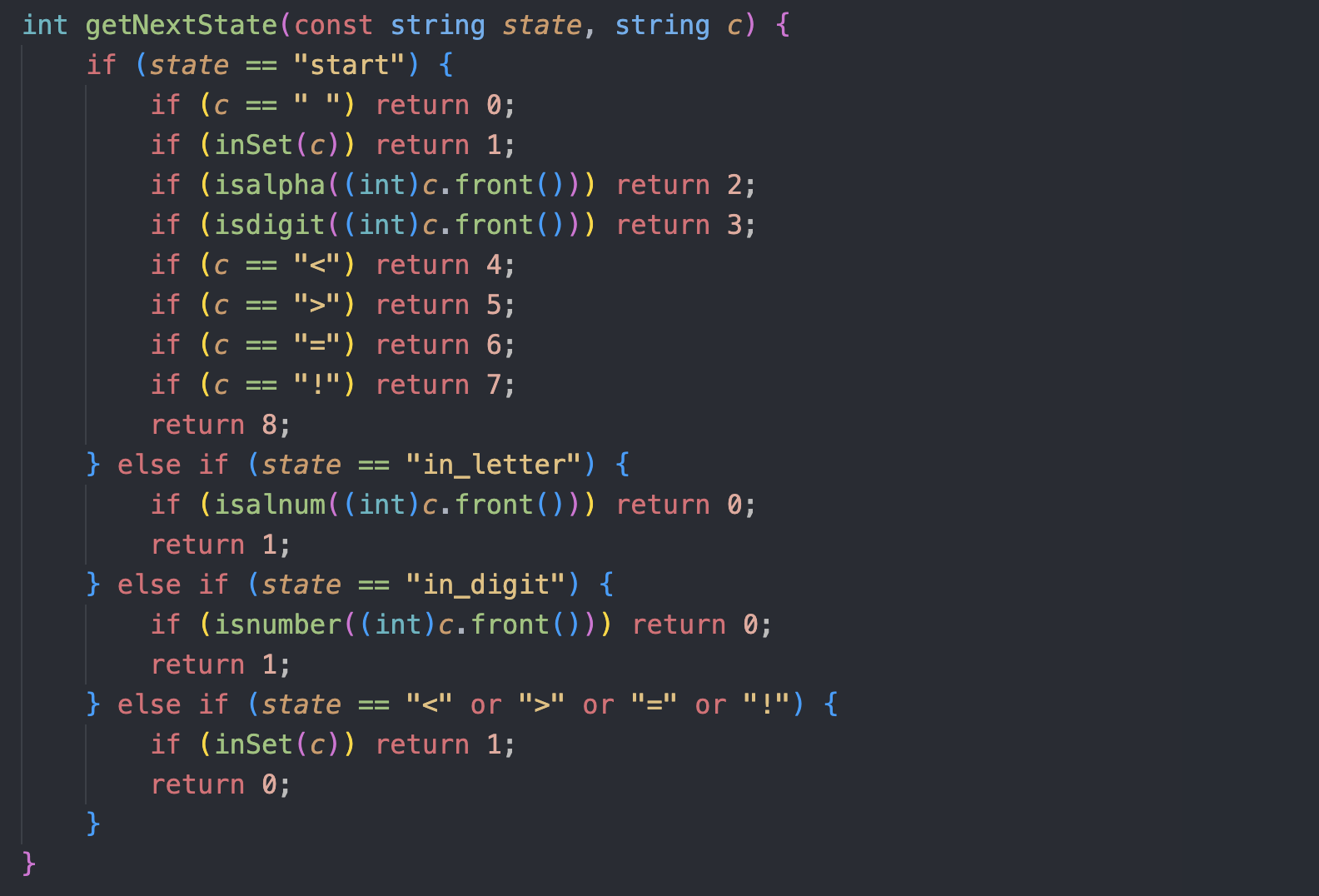
- 根据元祖
(currentState, nextChar)决定下一状态
- 根据元祖
读取下一字符串
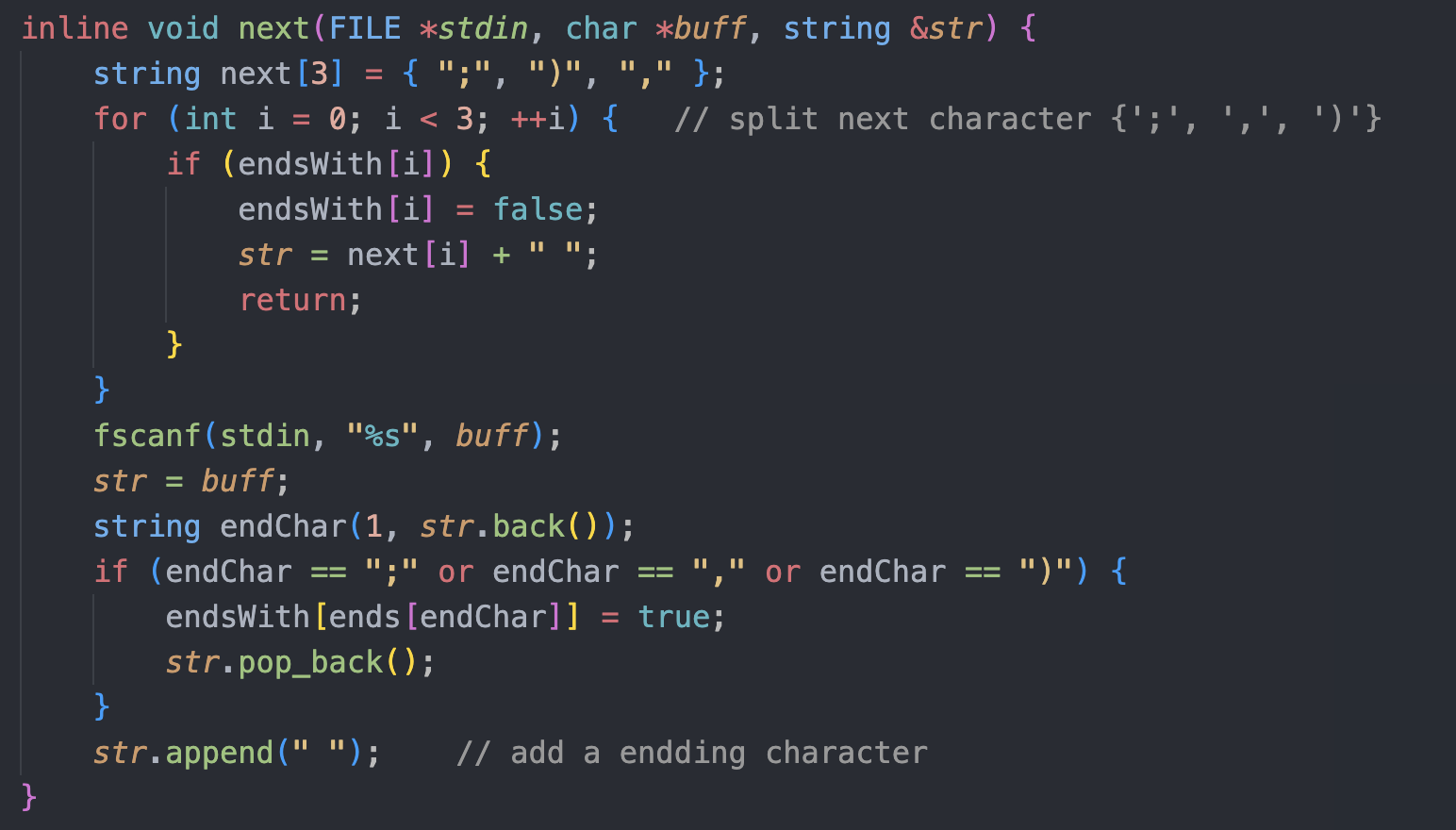
- 通过空格分割字符串, 一次读入一个字符串
- 为识别形如
str)、str;、str,的字符串, 需对末尾字符进行判断, 手动将str与末尾符号进行分割 - 通过在字符串末尾加入空格, 使自动机能够正确读入终结符并进入终态
启动状态机 (代码较长, 仅展示核心部分)
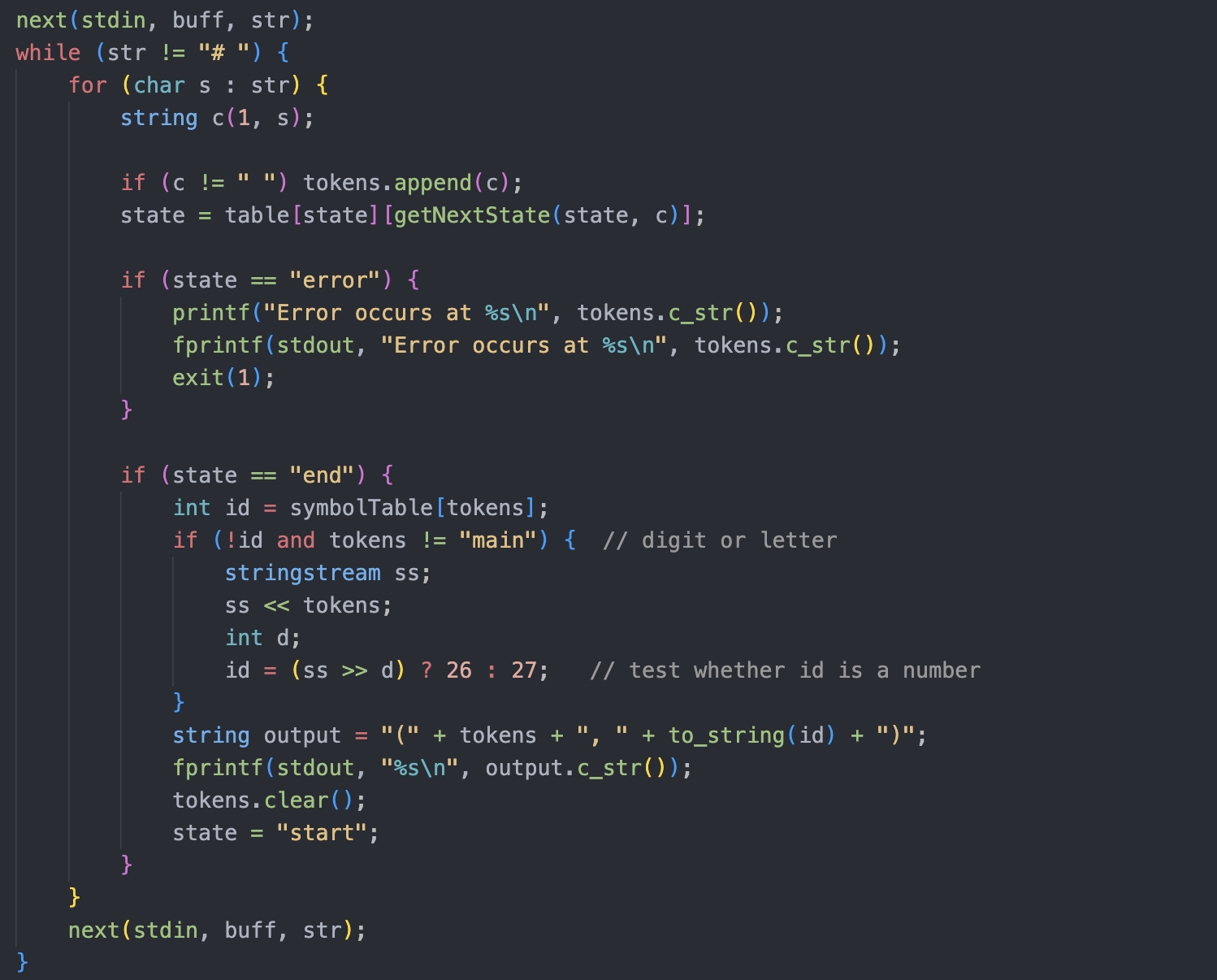
- 使用
tokens记录已经识别的符号 - 当自动机进入错误状态
error时, 报错并终止 - 当自动机进入终态
end时, 将识别的符号与编码进行链接, 写入文件中, 转向初态start继续识别 - 当遇到
#时, 文件结束, 自动机终止
- 使用
3.5 测试
3.5.1 合法性检查
在代码中加入合法性检查机制, 检测运行时附带的参数
若参数不够, 将打印使用文档到终端提示用户
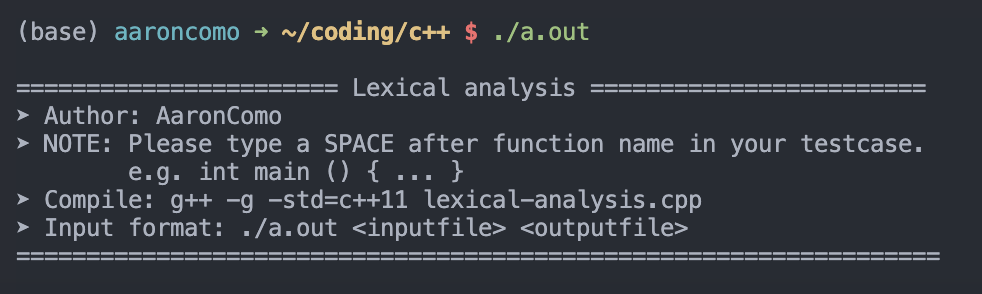
3.5.2 分析含错误的程序
测试程序
testcase2.c如下1 2 3 4 5 6
int main () { int i, j, k; long a = ?; return 0; } #
- 程序在第 3 行含有文法未定义的符号
?
- 程序在第 3 行含有文法未定义的符号
执行词法分析
终端输出错误出现的位置

查看输出文件
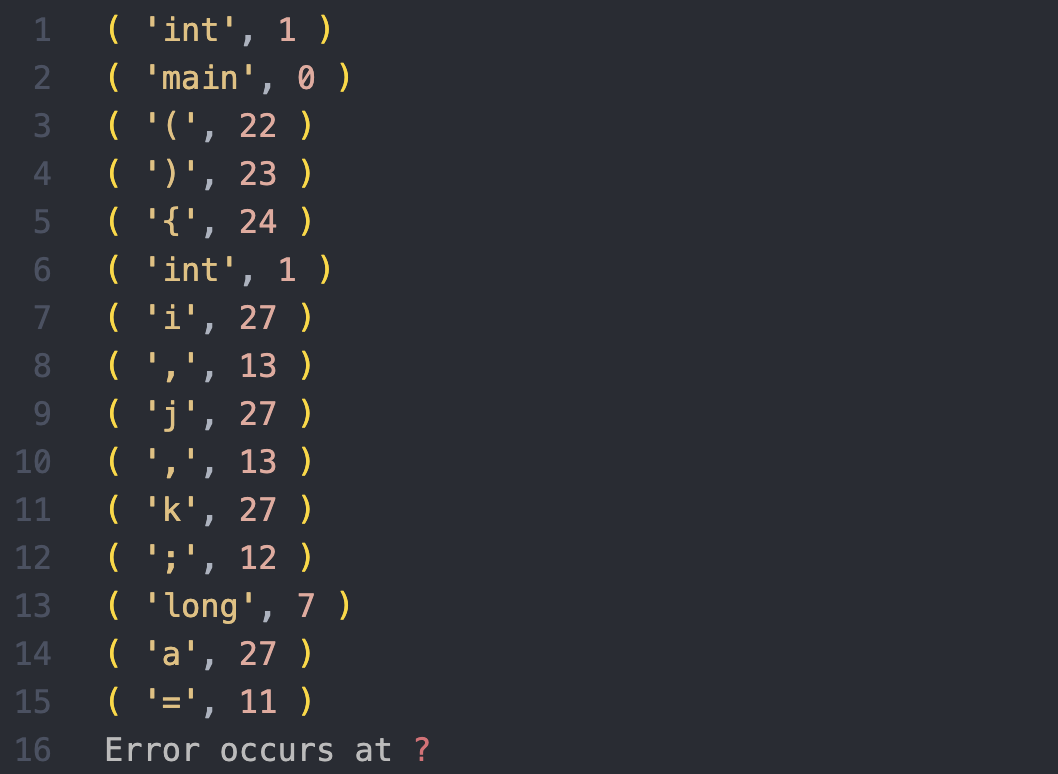
- 程序正确识别了
?前的语句, 并成功分析相应标识符 - 分析终止在未定义符号
- 程序正确识别了
3.5.3 分析正确程序
测试程序
testcase1.c如下1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
int main () { int a = 4, b = 5; if (a == b) { int alower = 3; b = alower * 100 / 2 - 8; } else if (a != b) { bool flag = false; flag = true; } do { long c = 99999239; for (int i = 0; i <= a; i = i + 1) { c -= 1; } } while (a > b) ; return 0; } #
执行词法分析
终端输出如下

查看输出文件
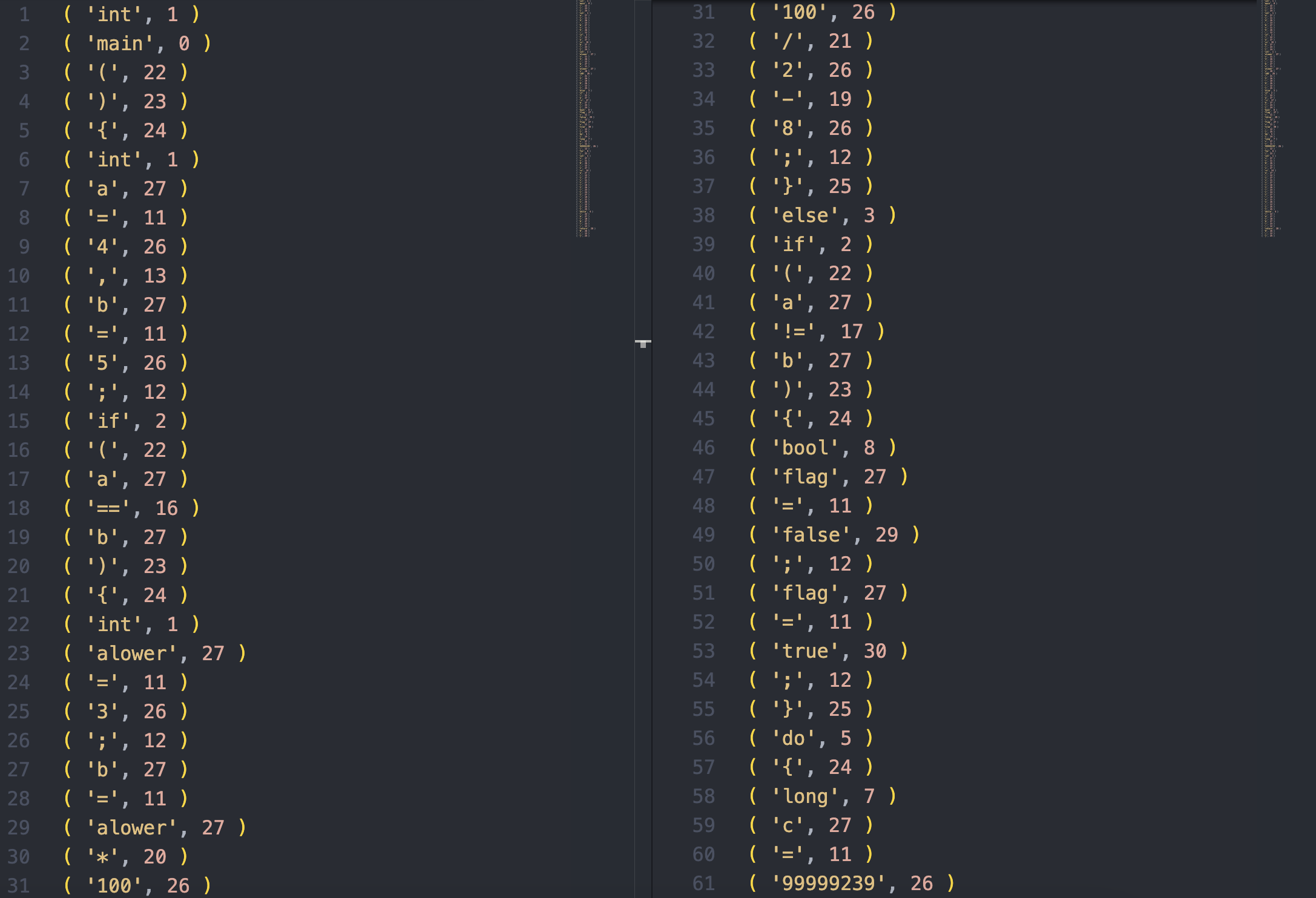
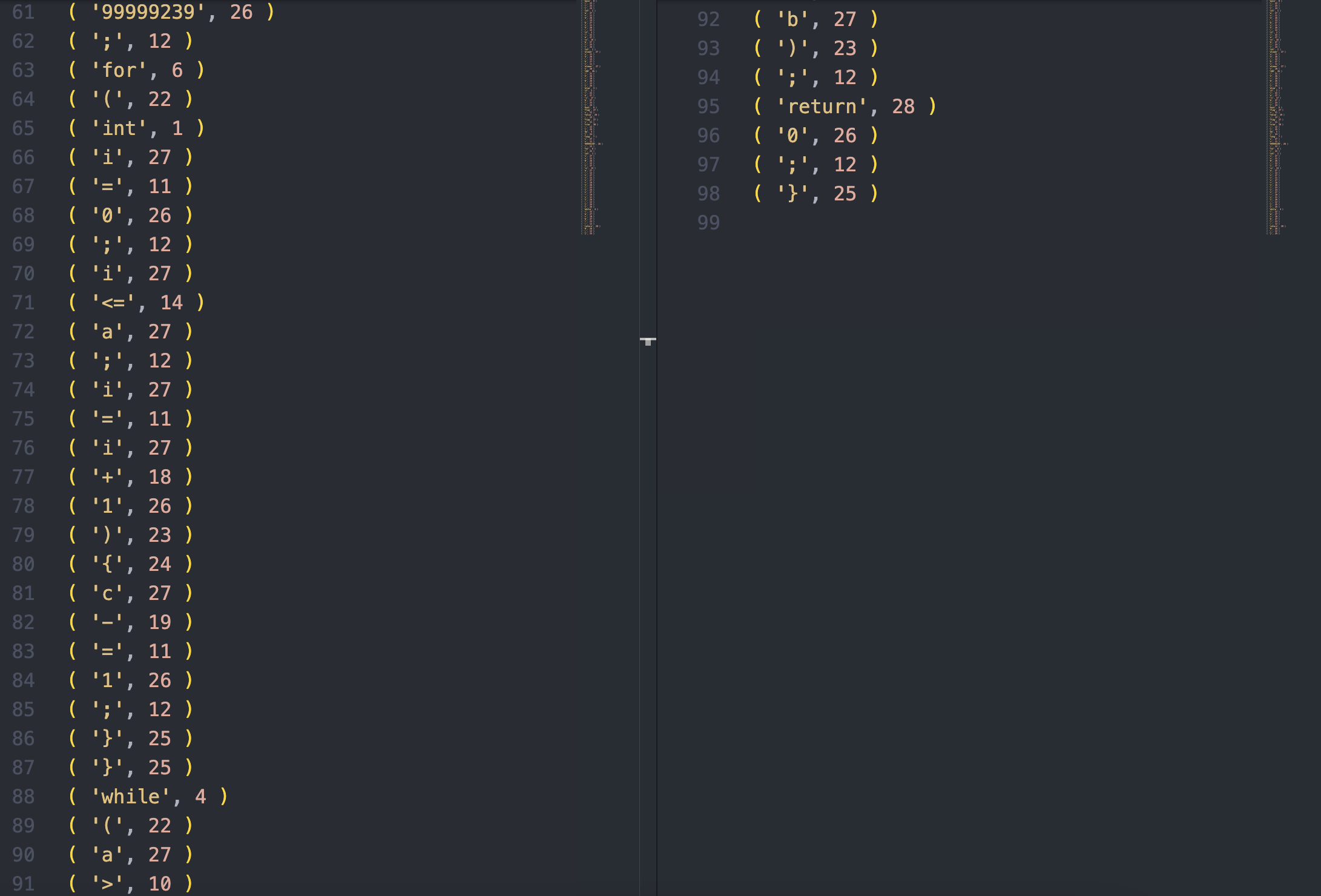
- 可以看到, 程序对测试文件进行了正确的词法分析
- 所有标识符均按照 3.2 中的标识符编码表进行了链接
This post is licensed under CC BY 4.0 by the author.