Lips Are Lying: Spotting the Temporal Inconsistency between Audio and Visual in Lip-Syncing DeepFakes
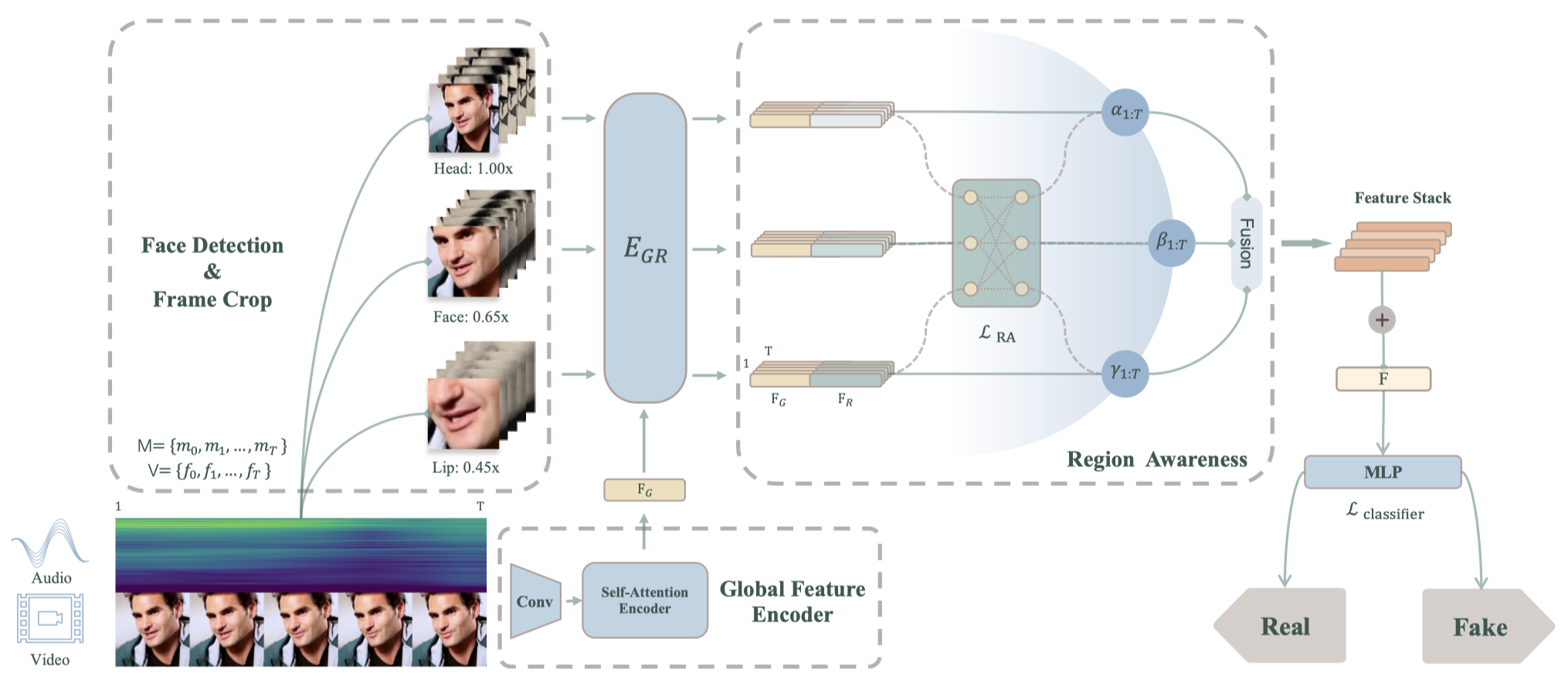

Abstract. In recent years, DeepFake technology has achieved unprecedented success in high-quality video synthesis, whereas these methods also pose potential and severe security threats to humanity. DeepFake can be bifurcated into entertainment applications like face swapping and illicit uses such as lip-syncing fraud. However, lip-forgery videos, which neither change identity nor have discernible visual artifacts, present a formidable challenge to existing DeepFake detection methods. Our preliminary experiments have shown that the effectiveness of the existing methods often drastically decreases or even fails when tackling lip-syncing videos.
In this paper, for the first time, we propose a novel approach dedicated to lip-forgery identification that exploits the inconsistency between lip movements and audio signals. We also mimic human natural cognition by capturing subtle biological links between lips and head regions to boost accuracy. To better illustrate the effectiveness and advances of our proposed method, we curate a high-quality LipSync dataset by employing the SOTA lip generator. We hope this high-quality and diverse dataset could be well served the further research on this challenging and interesting field. Experimental results show that our approach gives an average accuracy of more than 95.3% in spotting lip-syncing videos, significantly outperforming the baselines. Extensive experiments demonstrate the capability to tackle deepfakes and the robustness in surviving diverse input transformations. Our method achieves an accuracy of up to 90.2% in real-world scenarios (e.g., WeChat video call) and shows its powerful capabilities in real scenario deployment.
AVLip: A high-quality audio-visual dataset for lipsync detection
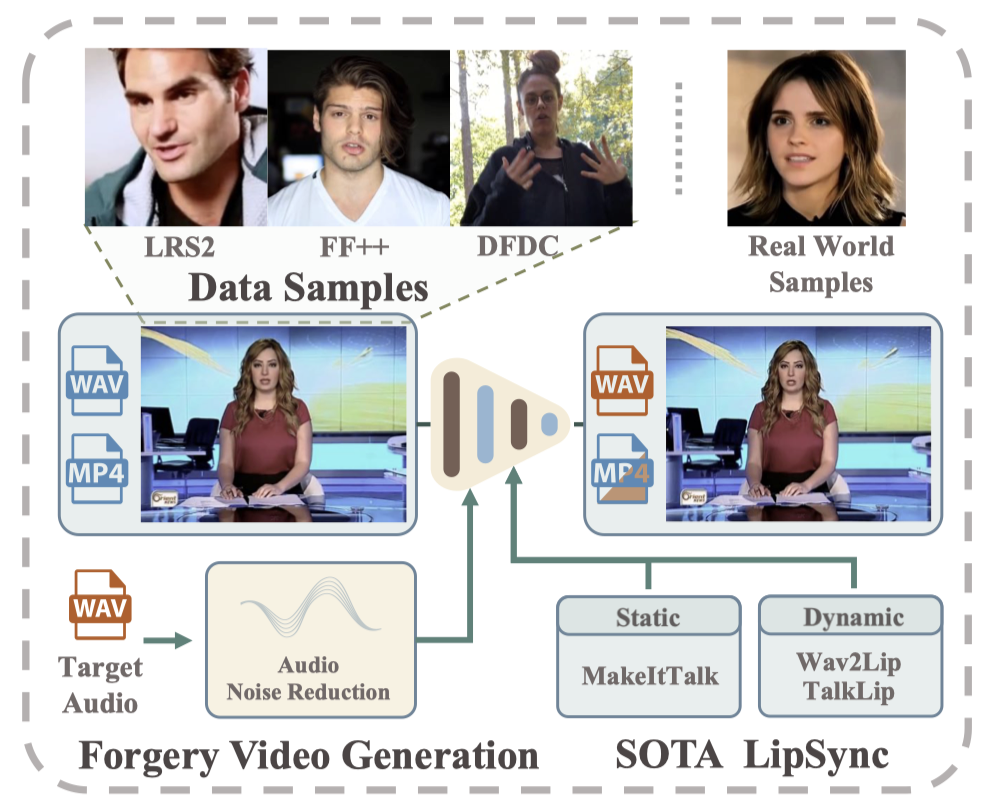
To the best of our knowledge, the majority of public DeepFake datasets consist solely of video or image sources, with no specialized dataset specifically dedicated to lip forgery detection available. To fill this gap, we construct a high-quality audio-visual dataset, AVLips, which contains 100,000 audiovisual samples generated by several state-of-the-art LipSync methods.
High quality. We employed a combination of static “MakeItTalk” [Zhou et al. 2020] and dynamic “Wav2Lip” [Prajwal et al. 2020], “TalkLip” [Wang et al. 2023] generation methods to simulate realistic lip movements. These generation methods are widely recognized as high-quality work in the academic community, capable of generating high-resolution videos while ensuring accurate lip movements. We applied a noise reduction algorithm to all audio samples before synthesis to reduce irrelevant background noise, ensuring the models can focus on speech content.
Diversity. Our dataset encompasses a wide range of scenarios, covering not only well-known public datasets but also real-world WeChat video calls. Our aim is for this collection to act as a catalyst for advancing real-time forgery detection. To better simulate the nuances of real-world conditions, we have employed six perturbation techniques — saturation, contrast, compression, Gaussian noise, Gaussian blur, and pixelation — at various degrees, thus ensuring the dataset’s realism and practical relevance.
We will open-source upon publication soon.
Requirements
- Python 3.10
1
2
conda create -n LipFD python==3.10
conda activate LipFD
- Python packages
1
pip install -r requirements.txt
Preprocess
Download AVLip dataset and put it in the root directory.
AVLip dataset folder structure.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
AVLip
├── 0_real
│ ├── 0.mp4
│ ...
├── 1_fake
│ ├── 0.mp4
│ └── ...
└── wav
├── 0_real
│ ├── 0.wav
│ └── ...
└── 1_fake
├── 0.wav
└── ...
Preprocess the dataset for training or validation.
1
python preprocess.py
It will create two folders under datasets/.
Preprocessed AVLip dataset folder structure.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
datasets
├── train
│ ├── 0_real
│ │ ├── 0_0.png
│ │ └── ...
│ └── 1_fake
│ ├── 0_0.png
│ └── ...
└── val
├── 0_real
│ ├── 0_0.png
│ └── ...
└── 1_fake
├── 0_0.png
└── ...
Validation
Download our pertained weights and save it in to checkpoints/ckpt.pth.
1
python validate.py --real_list_path ./datasets/val/0_real --fake_list_path ./datasets/val/1_fake --ckpt ./checkpoints/ckpt.pth
Train
First, edit --fake_list_path and --real_list_path in options/base_options.py.
Then, run python train.py.